



Free Advice On Deepseek
페이지 정보

본문
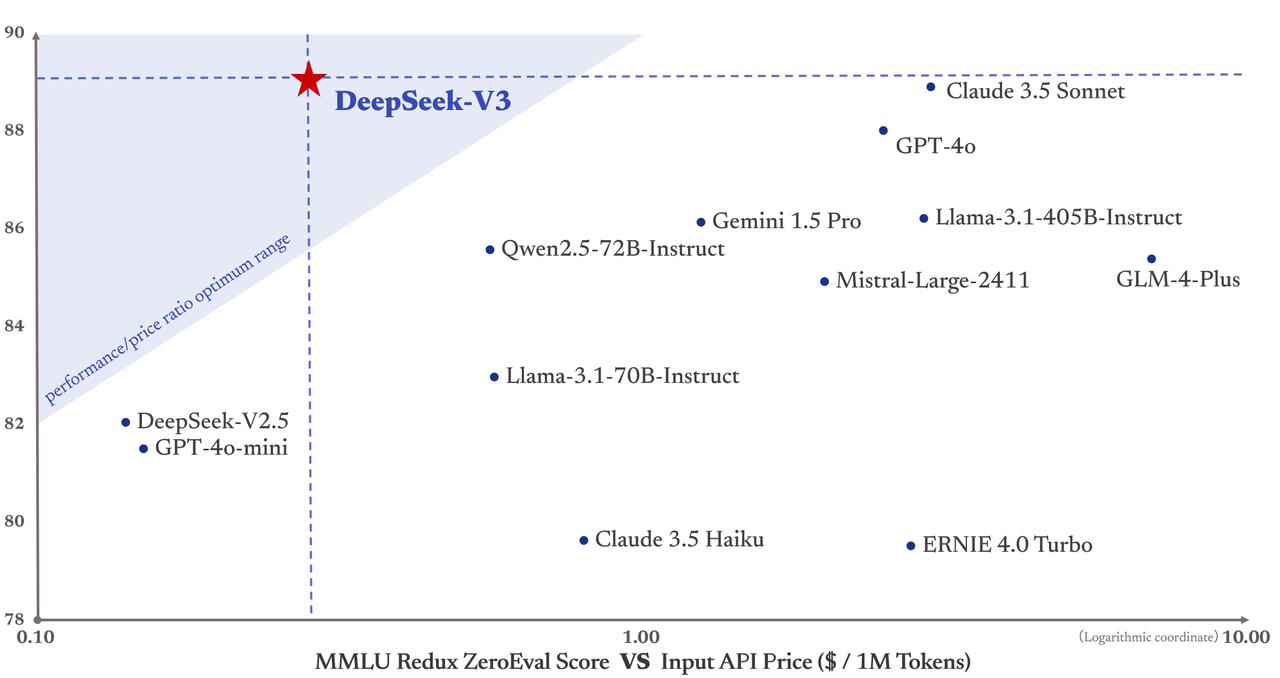 With a concentrate on ease of use, accessibility, and innovation, DeepSeek is not tied to any explicit country however is designed to serve a worldwide consumer base, regardless of geographical location. Another huge winner is Amazon: AWS has by-and-large failed to make their very own high quality mannequin, but that doesn’t matter if there are very top quality open source models that they will serve at far decrease costs than expected. On Windows: Open Command Prompt or PowerShell and do the same. Again, this was simply the ultimate run, not the total price, but it’s a plausible number. I nonetheless don’t consider that number. Distillation is less complicated for a corporation to do on its own models, as a result of they have full entry, but you can still do distillation in a somewhat more unwieldy means by way of API, and even, in case you get artistic, via chat shoppers. Combined with 119K GPU hours for the context size extension and 5K GPU hours for submit-training, DeepSeek-V3 costs only 2.788M GPU hours for its full training. Consequently, our pre- training stage is accomplished in less than two months and prices 2664K GPU hours. The training set, meanwhile, consisted of 14.8 trillion tokens; once you do all of the math it becomes apparent that 2.Eight million H800 hours is enough for coaching V3.
With a concentrate on ease of use, accessibility, and innovation, DeepSeek is not tied to any explicit country however is designed to serve a worldwide consumer base, regardless of geographical location. Another huge winner is Amazon: AWS has by-and-large failed to make their very own high quality mannequin, but that doesn’t matter if there are very top quality open source models that they will serve at far decrease costs than expected. On Windows: Open Command Prompt or PowerShell and do the same. Again, this was simply the ultimate run, not the total price, but it’s a plausible number. I nonetheless don’t consider that number. Distillation is less complicated for a corporation to do on its own models, as a result of they have full entry, but you can still do distillation in a somewhat more unwieldy means by way of API, and even, in case you get artistic, via chat shoppers. Combined with 119K GPU hours for the context size extension and 5K GPU hours for submit-training, DeepSeek-V3 costs only 2.788M GPU hours for its full training. Consequently, our pre- training stage is accomplished in less than two months and prices 2664K GPU hours. The training set, meanwhile, consisted of 14.8 trillion tokens; once you do all of the math it becomes apparent that 2.Eight million H800 hours is enough for coaching V3.
 Through the pre-coaching stage, coaching DeepSeek-V3 on every trillion tokens requires solely 180K H800 GPU hours, i.e., 3.7 days on our cluster with 2048 H800 GPUs. Here I should mention one other DeepSeek innovation: whereas parameters had been stored with BF16 or FP32 precision, they have been decreased to FP8 precision for calculations; 2048 H800 GPUs have a capacity of 3.97 exoflops, i.e. 3.Ninety seven billion billion FLOPS. Here is how to make use of Camel. Before we start, we would like to say that there are a large quantity of proprietary "AI as a Service" firms reminiscent of chatgpt, claude and so forth. We only want to make use of datasets that we are able to download and run domestically, no black magic. Assuming the rental worth of the H800 GPU is $2 per GPU hour, our complete training prices quantity to solely $5.576M. Moreover, when you truly did the math on the earlier question, you would understand that DeepSeek truly had an excess of computing; that’s as a result of DeepSeek actually programmed 20 of the 132 processing models on every H800 specifically to handle cross-chip communications. That’s based on CNBC, which obtained a memo from the agency’s chief AI officer informing personnel that DeepSeek’s servers function outside the U.S., elevating national safety considerations.
Through the pre-coaching stage, coaching DeepSeek-V3 on every trillion tokens requires solely 180K H800 GPU hours, i.e., 3.7 days on our cluster with 2048 H800 GPUs. Here I should mention one other DeepSeek innovation: whereas parameters had been stored with BF16 or FP32 precision, they have been decreased to FP8 precision for calculations; 2048 H800 GPUs have a capacity of 3.97 exoflops, i.e. 3.Ninety seven billion billion FLOPS. Here is how to make use of Camel. Before we start, we would like to say that there are a large quantity of proprietary "AI as a Service" firms reminiscent of chatgpt, claude and so forth. We only want to make use of datasets that we are able to download and run domestically, no black magic. Assuming the rental worth of the H800 GPU is $2 per GPU hour, our complete training prices quantity to solely $5.576M. Moreover, when you truly did the math on the earlier question, you would understand that DeepSeek truly had an excess of computing; that’s as a result of DeepSeek actually programmed 20 of the 132 processing models on every H800 specifically to handle cross-chip communications. That’s based on CNBC, which obtained a memo from the agency’s chief AI officer informing personnel that DeepSeek’s servers function outside the U.S., elevating national safety considerations.
It’s undoubtedly aggressive with OpenAI’s 4o and Anthropic’s Sonnet-3.5, and seems to be higher than Llama’s biggest model. Meta, in the meantime, is the most important winner of all. Apple can be a giant winner. Apple Silicon uses unified memory, which implies that the CPU, GPU, and NPU (neural processing unit) have entry to a shared pool of memory; which means Apple’s high-end hardware actually has the most effective consumer chip for inference (Nvidia gaming GPUs max out at 32GB of VRAM, whereas Apple’s chips go as much as 192 GB of RAM). Dramatically decreased memory requirements for inference make edge inference far more viable, and Apple has the best hardware for precisely that. H800s, nevertheless, are Hopper GPUs, they simply have much more constrained memory bandwidth than H100s due to U.S. I don’t know the place Wang received his data; I’m guessing he’s referring to this November 2024 tweet from Dylan Patel, which says that DeepSeek had "over 50k Hopper GPUs". Scale AI CEO Alexandr Wang stated they've 50,000 H100s. Nope. H100s were prohibited by the chip ban, however not H800s. Here’s the thing: a huge number of the improvements I explained above are about overcoming the lack of reminiscence bandwidth implied in utilizing H800s as a substitute of H100s.
Everyone assumed that coaching main edge fashions required more interchip memory bandwidth, but that is exactly what DeepSeek optimized both their model structure and infrastructure round. Precision and Depth: In situations where detailed semantic analysis and focused info retrieval are paramount, DeepSeek can outperform extra generalized models. If there's one lesson that entrepreneurs have realized prior to now few years, it’s this - staying skeptical of new technology could be an costly mistake. Distillation clearly violates the terms of service of assorted fashions, but the one technique to cease it's to really cut off access, by way of IP banning, charge limiting, and so on. It’s assumed to be widespread by way of mannequin training, and is why there are an ever-increasing variety of models converging on GPT-4o quality. It has the flexibility to assume by way of a problem, producing much higher high quality results, significantly in areas like coding, math, and logic (however I repeat myself). What does appear possible is that DeepSeek was capable of distill these models to give V3 top quality tokens to prepare on. Distillation is a technique of extracting understanding from one other model; you'll be able to send inputs to the instructor mannequin and record the outputs, and use that to train the student model.
- 이전글Which Website To Research Indoor Scooters Online 25.02.10
- 다음글The Medium Scooters Mistake That Every Beginner Makes 25.02.10
댓글목록
등록된 댓글이 없습니다.