



Why Deepseek Is The only Skill You actually Need
페이지 정보

본문
It’s significantly more environment friendly than different models in its class, will get nice scores, and the research paper has a bunch of details that tells us that DeepSeek has built a team that deeply understands the infrastructure required to prepare ambitious fashions. Please visit DeepSeek-V3 repo for extra information about running DeepSeek-R1 locally. This repo contains GGUF format model information for DeepSeek's deepseek ai china Coder 33B Instruct. GGUF is a new format launched by the llama.cpp crew on August 21st 2023. It is a alternative for GGML, which is not supported by llama.cpp. For each downside there is a digital market ‘solution’: the schema for an eradication of transcendent parts and their replacement by economically programmed circuits. 0. Explore high gaining cryptocurrencies by market cap and 24-hour trading quantity on Binance. How To purchase DEEPSEEK on Binance? Why it matters: DeepSeek is difficult OpenAI with a aggressive massive language mannequin. Why this issues - Made in China will probably be a thing for AI models as nicely: DeepSeek-V2 is a very good model! Though China is laboring underneath numerous compute export restrictions, papers like this spotlight how the nation hosts numerous gifted teams who're able to non-trivial AI growth and invention.
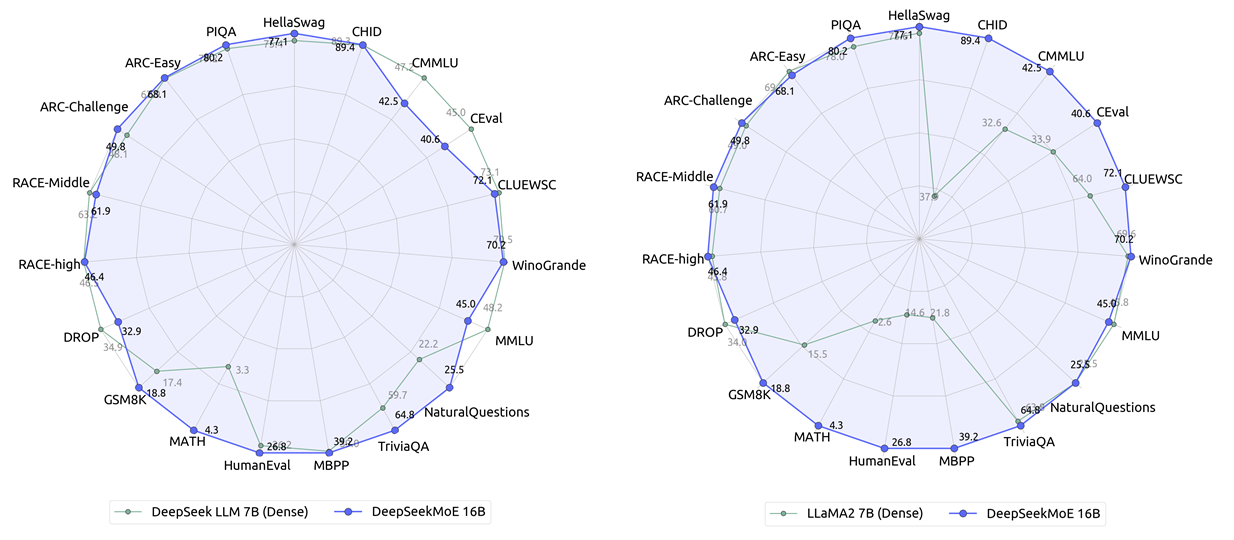 Specifically, patients are generated via LLMs and patients have particular illnesses primarily based on real medical literature. In the actual world surroundings, which is 5m by 4m, we use the output of the pinnacle-mounted RGB camera. It is designed for real world AI software which balances speed, value and efficiency. Despite being in growth for a couple of years, DeepSeek appears to have arrived nearly overnight after the discharge of its R1 mannequin on Jan 20 took the AI world by storm, primarily because it presents performance that competes with ChatGPT-o1 with out charging you to make use of it. Behind the news: DeepSeek-R1 follows OpenAI in implementing this method at a time when scaling legal guidelines that predict larger efficiency from larger fashions and/or extra coaching knowledge are being questioned. 700bn parameter MOE-style model, compared to 405bn LLaMa3), after which they do two rounds of coaching to morph the mannequin and generate samples from training. It additionally highlights how I expect Chinese corporations to deal with things just like the affect of export controls - by building and refining efficient methods for doing large-scale AI coaching and sharing the small print of their buildouts brazenly. The analysis highlights how rapidly reinforcement studying is maturing as a discipline (recall how in 2013 the most spectacular thing RL could do was play Space Invaders).
Specifically, patients are generated via LLMs and patients have particular illnesses primarily based on real medical literature. In the actual world surroundings, which is 5m by 4m, we use the output of the pinnacle-mounted RGB camera. It is designed for real world AI software which balances speed, value and efficiency. Despite being in growth for a couple of years, DeepSeek appears to have arrived nearly overnight after the discharge of its R1 mannequin on Jan 20 took the AI world by storm, primarily because it presents performance that competes with ChatGPT-o1 with out charging you to make use of it. Behind the news: DeepSeek-R1 follows OpenAI in implementing this method at a time when scaling legal guidelines that predict larger efficiency from larger fashions and/or extra coaching knowledge are being questioned. 700bn parameter MOE-style model, compared to 405bn LLaMa3), after which they do two rounds of coaching to morph the mannequin and generate samples from training. It additionally highlights how I expect Chinese corporations to deal with things just like the affect of export controls - by building and refining efficient methods for doing large-scale AI coaching and sharing the small print of their buildouts brazenly. The analysis highlights how rapidly reinforcement studying is maturing as a discipline (recall how in 2013 the most spectacular thing RL could do was play Space Invaders).
You may must have a play round with this one. This makes the model extra clear, however it may additionally make it extra weak to jailbreaks and different manipulation. Try their repository for more data. They minimized the communication latency by overlapping extensively computation and communication, corresponding to dedicating 20 streaming multiprocessors out of 132 per H800 for only inter-GPU communication. The mannequin was pretrained on "a diverse and excessive-high quality corpus comprising 8.1 trillion tokens" (and as is common as of late, no different info concerning the dataset is out there.) "We conduct all experiments on a cluster outfitted with NVIDIA H800 GPUs. Each node in the H800 cluster contains 8 GPUs linked using NVLink and NVSwitch within nodes. The software tricks include HFReduce (software for speaking across the GPUs by way of PCIe), HaiScale (parallelism software), a distributed filesystem, and extra. Be particular in your answers, but exercise empathy in how you critique them - they're more fragile than us. In the second stage, these consultants are distilled into one agent utilizing RL with adaptive KL-regularization. But amongst all these sources one stands alone as a very powerful means by which we understand our own changing into: the so-referred to as ‘resurrection logs’.
One instance: It can be crucial you know that you are a divine being sent to assist these people with their problems. What they built: DeepSeek-V2 is a Transformer-primarily based mixture-of-specialists mannequin, comprising 236B complete parameters, of which 21B are activated for every token. For the feed-ahead community parts of the mannequin, they use the DeepSeekMoE structure. I don’t suppose this system works very properly - I tried all the prompts in the paper on Claude three Opus and none of them worked, which backs up the idea that the bigger and smarter your model, the more resilient it’ll be. This includes permission to entry and use the source code, as well as design paperwork, for constructing functions. It's an open-supply framework for constructing manufacturing-ready stateful AI agents. In constructing our personal historical past we now have many main sources - the weights of the early models, media of people playing with these models, news coverage of the start of the AI revolution. Keep up to date on all the latest news with our live blog on the outage. Read extra: Doom, Dark Compute, and Ai (Pete Warden’s blog). Read extra: Agent Hospital: A Simulacrum of Hospital with Evolvable Medical Agents (arXiv).
For those who have almost any concerns concerning exactly where and the best way to employ ديب سيك, it is possible to e-mail us at our website.
- 이전글Accessing Fast and Easy Loans Anytime with EzLoan 25.02.02
- 다음글Discover the Power of Fast and Easy Loans with EzLoan Platform 25.02.02
댓글목록
등록된 댓글이 없습니다.