



Deepseek: That is What Professionals Do
페이지 정보

본문
 Briefly, DeepSeek feels very very similar to ChatGPT with out all the bells and whistles. It excels in areas which might be traditionally challenging for AI, like advanced arithmetic and code generation. Applications: Like other fashions, StarCode can autocomplete code, make modifications to code through directions, and even explain a code snippet in pure language. The stunning achievement from a relatively unknown AI startup becomes even more shocking when considering that the United States for years has worked to limit the supply of excessive-energy AI chips to China, citing nationwide security considerations. Users of R1 additionally level to limitations it faces due to its origins in China, namely its censoring of subjects thought-about sensitive by Beijing, together with the 1989 massacre in Tiananmen Square and the standing of Taiwan. In low-precision coaching frameworks, overflows and underflows are widespread challenges as a result of restricted dynamic range of the FP8 format, which is constrained by its diminished exponent bits. As we conclude our exploration of Generative AI’s capabilities, it’s clear success on this dynamic area demands both theoretical understanding and sensible experience. Applications: Gen2 is a game-changer across a number of domains: it’s instrumental in producing participating adverts, demos, and explainer movies for advertising and marketing; creating concept art and scenes in filmmaking and animation; creating instructional and training movies; and producing captivating content material for social media, entertainment, and interactive experiences.
Briefly, DeepSeek feels very very similar to ChatGPT with out all the bells and whistles. It excels in areas which might be traditionally challenging for AI, like advanced arithmetic and code generation. Applications: Like other fashions, StarCode can autocomplete code, make modifications to code through directions, and even explain a code snippet in pure language. The stunning achievement from a relatively unknown AI startup becomes even more shocking when considering that the United States for years has worked to limit the supply of excessive-energy AI chips to China, citing nationwide security considerations. Users of R1 additionally level to limitations it faces due to its origins in China, namely its censoring of subjects thought-about sensitive by Beijing, together with the 1989 massacre in Tiananmen Square and the standing of Taiwan. In low-precision coaching frameworks, overflows and underflows are widespread challenges as a result of restricted dynamic range of the FP8 format, which is constrained by its diminished exponent bits. As we conclude our exploration of Generative AI’s capabilities, it’s clear success on this dynamic area demands both theoretical understanding and sensible experience. Applications: Gen2 is a game-changer across a number of domains: it’s instrumental in producing participating adverts, demos, and explainer movies for advertising and marketing; creating concept art and scenes in filmmaking and animation; creating instructional and training movies; and producing captivating content material for social media, entertainment, and interactive experiences.
It's designed to supply extra natural, participating, and dependable conversational experiences, showcasing Anthropic’s commitment to developing consumer-pleasant and efficient AI options. Bash, and more. It may also be used for code completion and debugging. Applications: Software growth, code technology, code review, debugging help, and enhancing coding productivity. Innovations: The thing that units apart StarCoder from other is the extensive coding dataset it is educated on. Innovations: PanGu-Coder2 represents a significant advancement in AI-pushed coding models, providing enhanced code understanding and generation capabilities compared to its predecessor. It represents a significant development in AI’s capacity to grasp and visually represent advanced concepts, bridging the gap between textual directions and visible output. Additionally, it could perceive advanced coding necessities, making it a precious tool for developers seeking to streamline their coding processes and improve code quality. It excels in understanding and generating code in a number of programming languages, making it a invaluable tool for developers and software program engineers.
It excels in creating detailed, coherent photos from textual content descriptions. Unlike other fashions, Deepseek Coder excels at optimizing algorithms, and decreasing code execution time. What’s more, deepseek ai china’s newly released family of multimodal models, dubbed Janus Pro, reportedly outperforms DALL-E 3 as well as PixArt-alpha, Emu3-Gen, and Stable Diffusion XL, on a pair of industry benchmarks. If you're able and prepared to contribute it is going to be most gratefully acquired and can assist me to keep offering extra models, and to start out work on new AI tasks. As the Manager - Content and Growth at Analytics Vidhya, I help knowledge lovers study, share, and develop together. Applications: It could assist in code completion, write code from pure language prompts, debugging, and extra. More outcomes can be found within the analysis folder. We validate the proposed FP8 mixed precision framework on two mannequin scales just like DeepSeek-V2-Lite and DeepSeek-V2, coaching for approximately 1 trillion tokens (see more details in Appendix B.1). It accepts a context of over 8000 tokens.
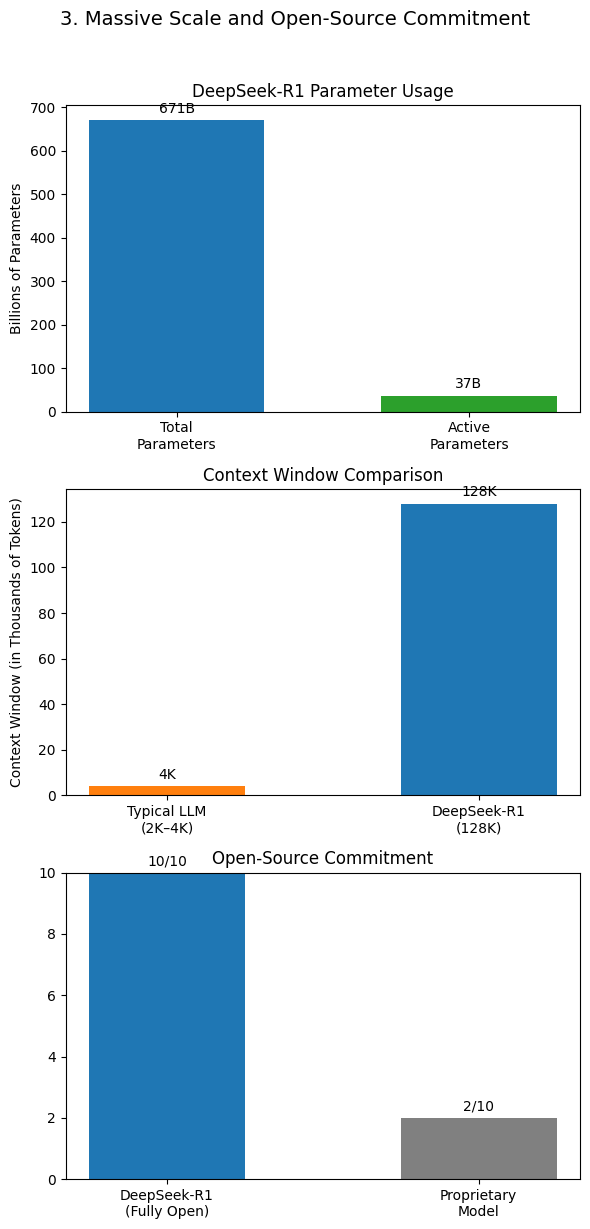
2. Extend context size from 4K to 128K using YaRN. This is basically a stack of decoder-only transformer blocks using RMSNorm, Group Query Attention, some type of Gated Linear Unit and Rotary Positional Embeddings. The researchers repeated the process several instances, every time utilizing the enhanced prover mannequin to generate greater-quality knowledge. An analogous course of can be required for the activation gradient. Furthermore, within the prefilling stage, to enhance the throughput and disguise the overhead of all-to-all and TP communication, we concurrently course of two micro-batches with comparable computational workloads, overlapping the attention and MoE of 1 micro-batch with the dispatch and mix of another. SDXL employs a complicated ensemble of knowledgeable pipelines, including two pre-skilled text encoders and a refinement model, ensuring superior image denoising and element enhancement. This mannequin marks a considerable leap in bridging the realms of AI and excessive-definition visual content material, providing unprecedented opportunities for professionals in fields the place visual detail and accuracy are paramount. Under this configuration, DeepSeek-V3 includes 671B total parameters, of which 37B are activated for each token. As illustrated in Figure 7 (a), (1) for activations, we group and scale parts on a 1x128 tile basis (i.e., per token per 128 channels); and (2) for weights, we group and scale components on a 128x128 block basis (i.e., ديب سيك per 128 input channels per 128 output channels).
- 이전글Are You Getting The Most Out From Your Test For ADHD In Adults? 25.02.01
- 다음글Toys For Men Adult Tools To Simplify Your Life Everyday 25.02.01
댓글목록
등록된 댓글이 없습니다.