



New Questions on Deepseek Answered And Why You should Read Every Word …
페이지 정보

본문
Listen to this story a company based mostly in China which goals to "unravel the mystery of AGI with curiosity has released DeepSeek LLM, a 67 billion parameter model educated meticulously from scratch on a dataset consisting of two trillion tokens. The license grants a worldwide, non-unique, royalty-free license for both copyright and patent rights, allowing the use, distribution, reproduction, and sublicensing of the mannequin and its derivatives. With a finger on the pulse of AI research and innovation, we carry a fresh perspective to the dynamic area, permitting readers to stay up-to-date on the most recent developments. The open source generative AI motion might be difficult to stay atop of - even for those working in or covering the field akin to us journalists at VenturBeat. Extended Context Window: deepseek ai china can process long text sequences, making it nicely-suited for tasks like advanced code sequences and detailed conversations. This technology "is designed to amalgamate harmful intent textual content with other benign prompts in a approach that kinds the ultimate immediate, making it indistinguishable for the LM to discern the real intent and disclose harmful information". Additionally, the "instruction following analysis dataset" launched by Google on November fifteenth, 2023, offered a comprehensive framework to guage DeepSeek LLM 67B Chat’s skill to follow directions across diverse prompts.
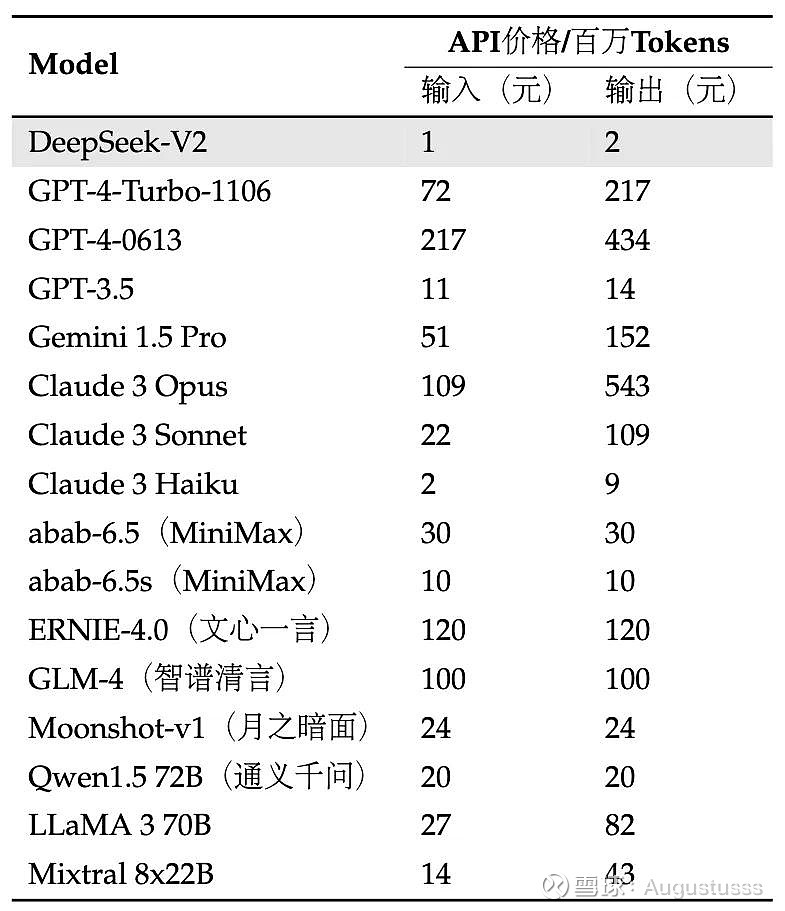 Example prompts producing utilizing this expertise: The resulting prompts are, ahem, extremely sus trying! So while various coaching datasets enhance LLMs’ capabilities, additionally they increase the chance of producing what Beijing views as unacceptable output. The most recent version, DeepSeek-V2, has undergone important optimizations in architecture and efficiency, with a 42.5% discount in training costs and a 93.3% reduction in inference costs. Mixture of Experts (MoE) Architecture: DeepSeek-V2 adopts a mixture of specialists mechanism, allowing the model to activate only a subset of parameters during inference. DeepSeek-V2 is a state-of-the-art language mannequin that makes use of a Transformer structure combined with an revolutionary MoE system and a specialised attention mechanism known as Multi-Head Latent Attention (MLA). Multi-Head Latent Attention (MLA): This novel consideration mechanism reduces the bottleneck of key-worth caches throughout inference, enhancing the mannequin's potential to handle long contexts. Access to intermediate checkpoints during the base model’s training process is offered, with usage subject to the outlined licence phrases. High-Flyer stated that its AI fashions did not time trades effectively although its inventory choice was fantastic by way of lengthy-time period value.
Example prompts producing utilizing this expertise: The resulting prompts are, ahem, extremely sus trying! So while various coaching datasets enhance LLMs’ capabilities, additionally they increase the chance of producing what Beijing views as unacceptable output. The most recent version, DeepSeek-V2, has undergone important optimizations in architecture and efficiency, with a 42.5% discount in training costs and a 93.3% reduction in inference costs. Mixture of Experts (MoE) Architecture: DeepSeek-V2 adopts a mixture of specialists mechanism, allowing the model to activate only a subset of parameters during inference. DeepSeek-V2 is a state-of-the-art language mannequin that makes use of a Transformer structure combined with an revolutionary MoE system and a specialised attention mechanism known as Multi-Head Latent Attention (MLA). Multi-Head Latent Attention (MLA): This novel consideration mechanism reduces the bottleneck of key-worth caches throughout inference, enhancing the mannequin's potential to handle long contexts. Access to intermediate checkpoints during the base model’s training process is offered, with usage subject to the outlined licence phrases. High-Flyer stated that its AI fashions did not time trades effectively although its inventory choice was fantastic by way of lengthy-time period value.
However it would not be used to carry out inventory trading. In addition the company acknowledged it had expanded its property too rapidly resulting in comparable buying and selling methods that made operations harder. In 2022, the company donated 221 million Yuan to charity because the Chinese government pushed corporations to do more in the identify of "widespread prosperity". In March 2022, High-Flyer suggested sure clients that have been delicate to volatility to take their cash back because it predicted the market was extra more likely to fall additional. The fashions would take on higher threat during market fluctuations which deepened the decline. High-Flyer stated it held stocks with strong fundamentals for a very long time and traded against irrational volatility that diminished fluctuations. Unlike other models, Deepseek Coder excels at optimizing algorithms, and lowering code execution time. In a current growth, the DeepSeek LLM has emerged as a formidable power in the realm of language fashions, boasting a formidable 67 billion parameters. A general use model that combines advanced analytics capabilities with an enormous 13 billion parameter rely, enabling it to carry out in-depth knowledge analysis and support complex determination-making processes.
In 2021, Fire-Flyer I was retired and was changed by Fire-Flyer II which cost 1 billion Yuan. It has been attempting to recruit deep learning scientists by providing annual salaries of up to 2 million Yuan. Seasoned AI enthusiast with a deep ardour for the ever-evolving world of artificial intelligence. In 2020, High-Flyer established Fire-Flyer I, a supercomputer that focuses on AI deep learning. At the tip of 2021, High-Flyer put out a public assertion on WeChat apologizing for its losses in property due to poor performance. In October 2023, High-Flyer announced it had suspended its co-founder and senior govt Xu Jin from work attributable to his "improper dealing with of a household matter" and having "a adverse affect on the corporate's reputation", following a social media accusation publish and a subsequent divorce courtroom case filed by Xu Jin's wife concerning Xu's extramarital affair.市场资讯 (27 October 2023). "幻方量化深夜处置婚外事件:涉事创始人停职,量化圈再被带到风口浪尖". Claude 3.5 Sonnet has proven to be the most effective performing fashions out there, and is the default model for our Free and Pro users.
When you cherished this information along with you want to acquire more info with regards to ديب سيك generously check out our own internet site.
- 이전글You're Welcome. Listed here are eight Noteworthy Tips On Deepseek 25.02.01
- 다음글10 Quick Tips For ADHD Diagnosis In Adults 25.02.01
댓글목록
등록된 댓글이 없습니다.